找到
35
篇与
xiaoeyv
相关的结果
- 第 2 页
-
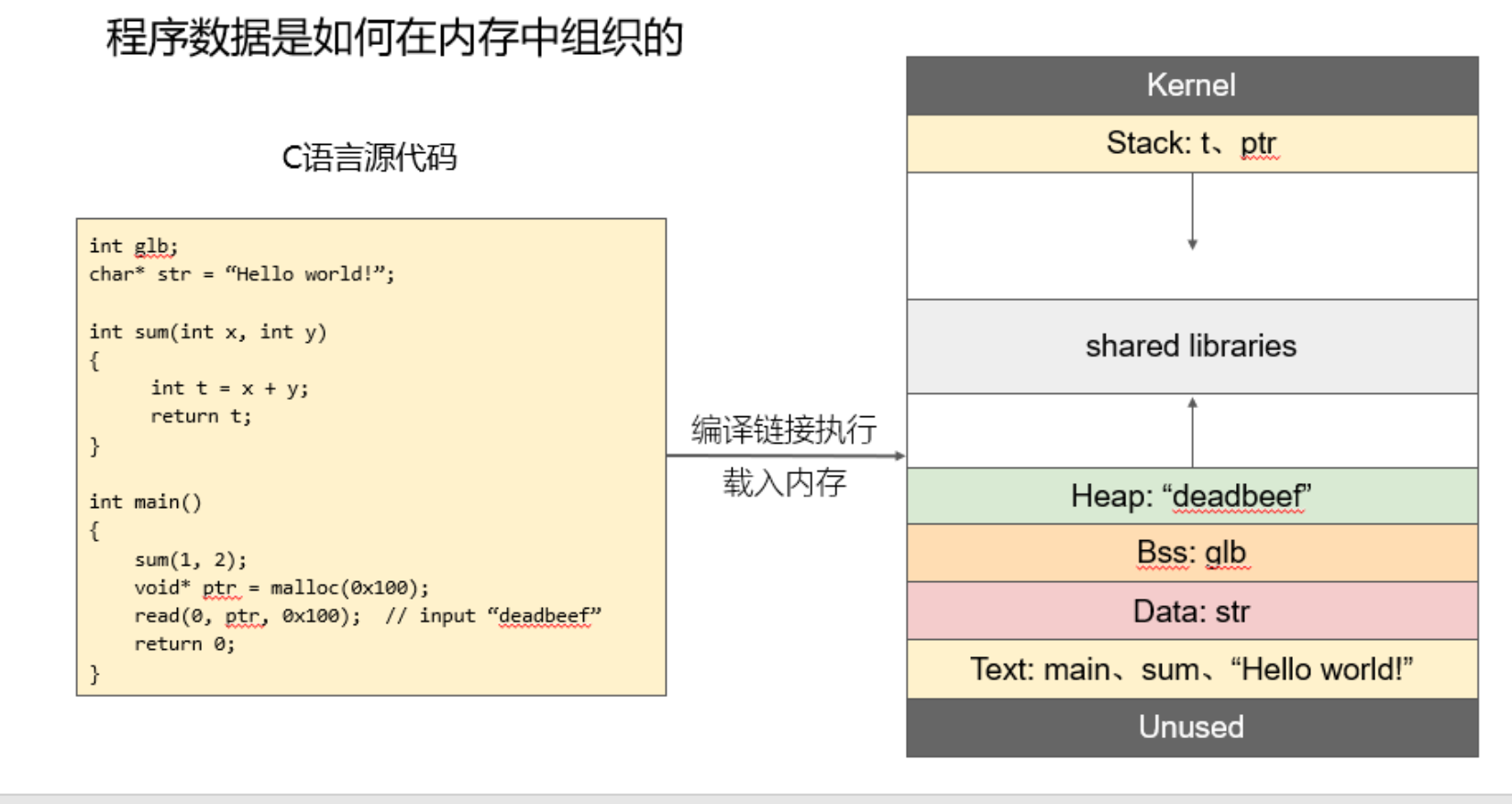
 程序数据是如何在内存中组织的 程序数据是如何在内存中组织的图片 如图,右侧是一片内存空间,地址由下往上升高。 具体参数: Kernel 代表操作系统的核心源码 1. Text(代码区): 作用:Text 区域存储程序的可执行代码,也就是程序的指令集。在 C 语言中,它包含了所有的函数体,如 main 函数、sum 函数以及程序中的字符串常量等。 特点: 只读:代码区通常是只读的,这是为了防止程序在运行时修改自己的代码,增加安全性。 不可变:一旦程序加载到内存,Text 区的内容通常不会发生变化,除非程序被重新编译。 存储结构:存储的是指令和常量数据,如字符串 "Hello world!"。 示例: int sum(int x, int y) { return x + y; }sum 函数存储在 Text 区域,它包含了程序的计算逻辑。在程序执行时,CPU 会从 Text 区读取并执行这些指令。 2. Data(数据区): 作用:Data 区域存储初始化过的全局变量和静态变量。所有在程序中显式初始化的全局变量会存储在这个区域。 特点: 初始化变量:如果你声明并初始化了全局变量,它们会被存储在 Data 区。例如 char* str = "Hello, world!"; 中的 str 就是一个全局变量。 持久性:这些变量在程序运行时会一直存在,并且在不同的函数之间共享。 示例: char* str = "Hello, world!"; // 这部分存储在Data区str 是一个初始化的全局变量,它存储在 Data 区,初始化时指向字符串 "Hello, world!"。 3. Bss(未初始化数据区): 作用:BSS 区域存储未初始化的全局变量或静态变量。它们在程序开始时没有显式地被赋值,但在程序执行时,操作系统会为它们分配零值(默认值)。 特点: 未初始化变量:在程序编译时,所有未初始化的全局变量和静态变量都会存储在 BSS 区。例如,声明一个全局变量但没有赋值,它就存储在 BSS 区。 默认值为零:BSS 区的变量在程序加载到内存时会被初始化为零或空指针(视类型而定)。 示例: int glb; // 这部分存储在BSS区,未初始化glb 是一个未初始化的全局变量,它会存储在 BSS 区,并在程序开始时默认被初始化为 0。 4. Heap(堆区): 作用:Heap 区用于动态内存分配。当程序运行时,需要分配内存时(例如通过 malloc 或 new),这些内存会被分配到堆区。程序员需要手动管理这些内存,使用 free 或 delete 来释放。 特点: 动态分配:Heap 区的内存大小是动态变化的,取决于程序运行时的内存分配需求。 管理复杂:程序员需要自行管理堆内存,否则可能会导致内存泄漏(未释放的内存)或悬挂指针(指向已释放的内存)。 示例: int* ptr = malloc(10 * sizeof(int)); // 动态分配内存,存储在Heap区通过 malloc 分配的内存会存储在 Heap 区。在此例中,ptr 指向堆区分配的内存空间。 5. Shared Libraries(共享库): 作用:Shared Libraries 区域存储程序在运行时加载的共享库。共享库包含了多个程序共享的代码,减少了内存的使用。操作系统会在程序加载时把这些共享库加载到内存中,并将它们映射到程序的地址空间中。 特点: 动态链接:共享库在程序运行时被动态链接,不同程序可以共享同一个库,节省内存。 共享代码:多个程序可以同时使用同一个库的代码,避免了重复加载。 示例: 假设程序中使用了 printf 函数,这个函数通常会从标准 C 库(如 libc)中加载。libc 就是一个共享库。 共享库的代码通常会存储在程序的内存区域中,当程序调用 printf 时,会跳转到 libc 中对应的实现。 6. Stack(栈区): 作用:Stack 区用于存储函数的局部变量、函数参数以及返回地址。当函数被调用时,栈会存储该函数的返回地址、局部变量以及其他调用信息。栈在函数调用时自动分配,并在函数返回时释放。 特点: 自动管理:栈区的内存由操作系统自动管理,程序员不需要手动分配和释放。 先进后出:栈的内存分配遵循 LIFO(后进先出)原则,每当一个函数调用时,栈会压入相应的信息;当函数返回时,栈会弹出这些信息。 溢出问题:栈的大小是有限的,如果栈空间过大(例如递归深度过深),可能会导致栈溢出(stack overflow)。 示例: void sum(int a, int b) { int c = a + b; // 局部变量c存储在栈区 }函数 sum 的参数 a、b 和局部变量 c 都存储在栈区。当函数执行时,它们会被压入栈;函数返回后,它们会从栈中弹出。 总结: Text 区存储程序的可执行代码。 Data 区存储已初始化的全局变量。 BSS 区存储未初始化的全局变量。 Heap 区存储动态分配的内存。 Shared Libraries 区存储共享库。 Stack 区存储函数的局部变量、参数和返回地址。
程序数据是如何在内存中组织的 程序数据是如何在内存中组织的图片 如图,右侧是一片内存空间,地址由下往上升高。 具体参数: Kernel 代表操作系统的核心源码 1. Text(代码区): 作用:Text 区域存储程序的可执行代码,也就是程序的指令集。在 C 语言中,它包含了所有的函数体,如 main 函数、sum 函数以及程序中的字符串常量等。 特点: 只读:代码区通常是只读的,这是为了防止程序在运行时修改自己的代码,增加安全性。 不可变:一旦程序加载到内存,Text 区的内容通常不会发生变化,除非程序被重新编译。 存储结构:存储的是指令和常量数据,如字符串 "Hello world!"。 示例: int sum(int x, int y) { return x + y; }sum 函数存储在 Text 区域,它包含了程序的计算逻辑。在程序执行时,CPU 会从 Text 区读取并执行这些指令。 2. Data(数据区): 作用:Data 区域存储初始化过的全局变量和静态变量。所有在程序中显式初始化的全局变量会存储在这个区域。 特点: 初始化变量:如果你声明并初始化了全局变量,它们会被存储在 Data 区。例如 char* str = "Hello, world!"; 中的 str 就是一个全局变量。 持久性:这些变量在程序运行时会一直存在,并且在不同的函数之间共享。 示例: char* str = "Hello, world!"; // 这部分存储在Data区str 是一个初始化的全局变量,它存储在 Data 区,初始化时指向字符串 "Hello, world!"。 3. Bss(未初始化数据区): 作用:BSS 区域存储未初始化的全局变量或静态变量。它们在程序开始时没有显式地被赋值,但在程序执行时,操作系统会为它们分配零值(默认值)。 特点: 未初始化变量:在程序编译时,所有未初始化的全局变量和静态变量都会存储在 BSS 区。例如,声明一个全局变量但没有赋值,它就存储在 BSS 区。 默认值为零:BSS 区的变量在程序加载到内存时会被初始化为零或空指针(视类型而定)。 示例: int glb; // 这部分存储在BSS区,未初始化glb 是一个未初始化的全局变量,它会存储在 BSS 区,并在程序开始时默认被初始化为 0。 4. Heap(堆区): 作用:Heap 区用于动态内存分配。当程序运行时,需要分配内存时(例如通过 malloc 或 new),这些内存会被分配到堆区。程序员需要手动管理这些内存,使用 free 或 delete 来释放。 特点: 动态分配:Heap 区的内存大小是动态变化的,取决于程序运行时的内存分配需求。 管理复杂:程序员需要自行管理堆内存,否则可能会导致内存泄漏(未释放的内存)或悬挂指针(指向已释放的内存)。 示例: int* ptr = malloc(10 * sizeof(int)); // 动态分配内存,存储在Heap区通过 malloc 分配的内存会存储在 Heap 区。在此例中,ptr 指向堆区分配的内存空间。 5. Shared Libraries(共享库): 作用:Shared Libraries 区域存储程序在运行时加载的共享库。共享库包含了多个程序共享的代码,减少了内存的使用。操作系统会在程序加载时把这些共享库加载到内存中,并将它们映射到程序的地址空间中。 特点: 动态链接:共享库在程序运行时被动态链接,不同程序可以共享同一个库,节省内存。 共享代码:多个程序可以同时使用同一个库的代码,避免了重复加载。 示例: 假设程序中使用了 printf 函数,这个函数通常会从标准 C 库(如 libc)中加载。libc 就是一个共享库。 共享库的代码通常会存储在程序的内存区域中,当程序调用 printf 时,会跳转到 libc 中对应的实现。 6. Stack(栈区): 作用:Stack 区用于存储函数的局部变量、函数参数以及返回地址。当函数被调用时,栈会存储该函数的返回地址、局部变量以及其他调用信息。栈在函数调用时自动分配,并在函数返回时释放。 特点: 自动管理:栈区的内存由操作系统自动管理,程序员不需要手动分配和释放。 先进后出:栈的内存分配遵循 LIFO(后进先出)原则,每当一个函数调用时,栈会压入相应的信息;当函数返回时,栈会弹出这些信息。 溢出问题:栈的大小是有限的,如果栈空间过大(例如递归深度过深),可能会导致栈溢出(stack overflow)。 示例: void sum(int a, int b) { int c = a + b; // 局部变量c存储在栈区 }函数 sum 的参数 a、b 和局部变量 c 都存储在栈区。当函数执行时,它们会被压入栈;函数返回后,它们会从栈中弹出。 总结: Text 区存储程序的可执行代码。 Data 区存储已初始化的全局变量。 BSS 区存储未初始化的全局变量。 Heap 区存储动态分配的内存。 Shared Libraries 区存储共享库。 Stack 区存储函数的局部变量、参数和返回地址。
-
Kali关闭地址空间布局随机化(ASLR) 检查当前 ASLR 状态 cat /proc/sys/kernel/randomize_va_space 返回 0:ASLR 完全关闭 返回 1:部分随机(栈、堆、共享库等随机,但主程序可能不随机) 返回 2:完全随机(默认值,最安全,但对于 Pwn 最不友好) 临时关闭(当前终端有效) echo 0 | sudo tee /proc/sys/kernel/randomize_va_space针对单个程序关闭 ASLR setarch `uname -m` -R ./your_pwn_programsetarch + -R 参数会让该进程的地址空间 不随机化
-
P13100 [FJCPC 2025] 众数 题解 P13100 [FJCPC 2025] 众数 题解 读题 题目数学公式有点多,先简单复述一下题意: 我们有一串数字,比如说 [4, 1, 5, 3]。 “第一个前缀” 就是前面一个数字:[4]。 “第二个前缀” 就是前面两个数字:[4,1]。 “第三个前缀” 就是前三个数字:[4,1,5]。 以此类推... 对于第 $ k $ 个前缀(长度为 $ k $ ),我们可以从里面任意挑选一些位置,至少要选一个。 比如前缀 [4,1,5],可以选 {4},也可以选 {1},也可以选 {5},也可以选 {4,1},甚至可以选 {4,1,5},总共有 $2^k-1$ 种选法。(子集个数公式,这个高一数学会讲,套公式就是快) 然后在选出来的这堆数里,找到最小和最大的那两个数相加 例如子集 {4,1},最小是 1,最大是 4,1+4=5; 例如子集 {5},最小也是最大都是 5,5+5=10; 例如子集 {4,1,5},最小是 1,最大是 5,1+5=6。 我们把所有子集算出来的值放在一起,看哪个数字出现得最多。(这里就不举例了,一个一个算太累了) 特殊情况: 如果出现最多次数的数有好几个,比如“5”和“7”都出现了三次,就选大的那个数“7”作答案。 开始想算法 刚开始想用map做,但因为子集的数量是指数级的($2^{k-1}$),所以如果用map记录来做时间复杂度就是O( $ 2^k $),这里n有 $ 10^6 $ 根本跑不动。(不信可以试一试) 然后就想用数论优化了: 通过样例发现规律:众数的取值仅与当前前缀的最小值、最大值及其出现次数相关。 具体如何推导呢?我们分类讨论吧。这里我们把除了最小值和最大值的其他元素叫做中间元素。 如果存在中间元素,或最小值出现次数不少于 $ 2 $ 包含最小值和最大值的子集,无论是否包含中间元素,其 $ \min $ 必为最小值、$ \max $ 必为最大值,这类子集数量最多。即使存在次数相同的其他和,最小值+最大值也是其中最大的。 所以:众数为最小值+最大值。 若没有中间元素且最小值仅出现 $ 1 $ 次 此时元素只有 $ 1 $ 个最小值和若干最大值,包含最小值和最大值的子集与仅包含最大值的子集数量相同,但 $ 2\times 最大值 $ 更大。 所以:众数为 $ 2\times 最大值 $。 然后我们就可以愉快地写代码啦~ #include <bits/stdc++.h> #define ll long long using namespace std; int main() { ios::sync_with_stdio ( false ); cin.tie ( nullptr ); int T; cin >> T; while ( T-- ) { int n; cin >> n; ll minv = 0, maxv = 0; ll cmin = 0, cmax = 0; for ( int i = 1; i <= n; i++ ) { ll x; cin >> x; if ( i == 1 ) { cout << x * 2 << ' '; minv = maxv = x; cmin = cmax = 1; } else { if ( x == maxv ) { cmax++; } else if ( x > maxv ) { maxv = x; cmax = 1; } else if ( x == minv ) { cmin++; } else if ( x < minv ) { minv = x; cmin = 1; } ll cmid = i - cmin - cmax; if ( cmid > 0 || cmin >= 2 ) { cout << minv + maxv << ' '; } else { cout << maxv * 2 << ' '; } } } cout << endl; } return 0; }
-
C++求联通块数量 本文使用了下面五种方法求联通块数量: 并查集 深度优先搜索DFS 广度优先搜索BFS Floyd Kruskal #include<bits/stdc++.h> using namespace std; const int N = 110; const int M = 10010; int n, m; vector<int> g[N]; int ans = 0; // 1.并查集 int pre[N]; int find ( int x ) { return x == pre[x] ? pre[x] : pre[x] = find ( pre[x] ); } void merge ( int x, int y ) { int rx = find ( x ), ry = find ( y ); if ( rx != ry ) { pre[rx] = ry; } } void solveA() { for ( int i = 1; i <= n; i++ ) { pre[i] = i; } for ( int i = 1; i <= m; i++ ) { int u, v; cin >> u >> v; g[u].emplace_back ( v ); g[v].emplace_back ( u ); merge ( u, v ); } for ( int i = 1; i <= n; i++ ) { if ( pre[i] == i ) { ans++; } } cout << ans; } // 2.深搜 int vis[N]; void dfs ( int x ) { for ( auto &u : g[x] ) { if ( vis[u] ) { continue; } vis[u] = true; dfs ( u ); } } void solveB() { for ( int i = 1; i <= m; i++ ) { int u, v; cin >> u >> v; g[u].emplace_back ( v ); g[v].emplace_back ( u ); } for ( int i = 1; i <= n; i++ ) { if ( !vis[i] ) { dfs ( i ); ans++; } } cout << ans; } // 3.广搜 void bfs ( int x ) { queue<int> q; q.emplace ( x ); while ( !q.empty() ) { int u = q.front(); q.pop(); for ( auto &v : g[u] ) { if ( vis[v] ) { continue; } vis[v] = true; q.emplace ( v ); } } } void solveC() { for ( int i = 1; i <= m; i++ ) { int u, v; cin >> u >> v; g[u].emplace_back ( v ); g[v].emplace_back ( u ); } for ( int i = 1; i <= n; i++ ) { if ( !vis[i] ) { bfs ( i ); ans++; } } cout << ans; } // 4.Floyd int adj[N][N]; void solveD() { for ( int i = 1; i <= n; i++ ) { adj[i][i] = 1; } for ( int i = 1; i <= m; i++ ) { int u, v; cin >> u >> v; adj[u][v] = adj[v][u] = 1; } ans = 0; for ( int k = 1; k <= n; k++ ) { for ( int i = 1; i <= n; i++ ) { for ( int j = 1; j <= n; j++ ) { if ( adj[i][k] && adj[k][j] ) { adj[i][j] = 1; } } } } for ( int i = 1; i <= n; i++ ) { if ( !vis[i] ) { ans++; for ( int j = 1; j <= n; j++ ) { if ( adj[i][j] ) { vis[j] = true; } } } } cout << ans; } // 5.Kruskal 最小生成森林 struct Edge { int u, v; } e[M]; void solveE() { for ( int i = 1; i <= n; i++ ) { pre[i] = i; } for ( int i = 1; i <= m; i++ ) { int u, v; cin >> u >> v; e[i] = {u, v}; } ans = n; for ( int i = 1; i <= m; i++ ) { int u = e[i].u, v = e[i].v; int ru = find ( u ), rv = find ( v ); if ( ru != rv ) { merge ( ru, rv ); ans--; } } cout << ans; } // int main() { cin >> n >> m; // solveA(); // solveB(); // solveC(); // solveD(); solveE(); return 0; }
-
AStyle v2.03 帮助文件中文版 AStyle 2.03 维护者:Jim Pattee 原始作者:Tal Davidson 用法 astyle [选项] 源文件1.cpp 源文件2.cpp [...] astyle [选项] < 原始文件 > 美化后文件 注意: 格式化后文件保留原文件名,原文件重命名为 *.orig 支持通配符 *、? 可通过 --recursive 或 -r 递归处理目录 默认选项文件 AStyle 会按以下顺序查找并加载默认配置: 环境变量 ARTISTIC_STYLE_OPTIONS $HOME/.astylerc %USERPROFILE%\astylerc 提示:默认配置中的长选项可省略前导 --。括号风格(--style 或 -A) 样式名别名标记特点Allmanansi, bsd, break-A1分离括号Javaattach-A2紧贴括号Kernighan & Ritchiek\&r, k/r-A3Linux 风格括号Stroustrup—-A4Stroustrup 括号Whitesmith—-A5分离且缩进的括号Banner—-A6紧贴且缩进的括号GNU—-A7分离且缩进的括号Linux—-A8条件最小缩进半级Horstmann—-A9行内括号,缩进 switchOne True Braceotbs-A10为所有条件添加括号Pico—-A11行内括号,保留单行块/语句Lisp—-A12紧贴括号,保留单行语句缩进选项 制表符与空格 --indent=spaces=# 或 -s#:使用 # 个空格,默认 4 --indent=tab=# 或 -t#:使用制表符,假设每级等于 # 个空格,默认 4 强制制表符:--indent=force-tab=# / -T# 混合空格与制表符:--indent=force-tab-x=# / -xT# 语法块缩进 -C, --indent-classes // class 内部缩进 -S, --indent-switches // switch 内部缩进 -K, --indent-cases // case 语句缩进 -N, --indent-namespaces // namespace 内容缩进 -L, --indent-labels // 标签缩进一级 -w, --indent-preprocessor // 缩进多行 #define -Y, --indent-col1-comments // 缩进第一列注释 -m#, --min-conditional-indent=# // 条件体最小缩进(0–3,默认 2) -M#, --max-instatement-indent=# // 连续语句最大缩进(40–120,默认 40)填充与格式化 空行管理 -f, --break-blocks:隔离不同代码块 -F, --break-blocks=all:额外在 else/catch 等处插入空行 运算符与括号空格 -p, --pad-oper:操作符两侧空格 -P, --pad-paren:括号内外空格 细化:-d/-D/-xd 等 保持或拆分 -O:保持单行块 -o:保持多语句行 其他 -j:添加条件语句括号 -J:添加单行括号 -c:制表符转空格 -y:闭合头前换行 -e:拆分 else if 其他常用选项 --suffix=#### // 自定义原文件后缀 -n, --suffix=none // 不保留备份 -r, -R // 递归 --exclude=路径 // 排除文件/目录 -v, --verbose // 详细模式 -q, --quiet // 安静模式 -Z, --preserve-date // 保留修改日期 --lineend=windows|linux|macold // 强制行尾样式 -V, --version // 显示版本 -h, --help // 帮助信息重点: 使用 -A 选择括号风格 通过 -s/-t 管理缩进方式 -p/-P/-d 细调空格 -r 批量处理目录

![P13100 [FJCPC 2025] 众数 题解](http://blog.xiaoeyv.com/usr/themes/joe/assets/images/thumb/01.jpg)

